
Disclaimer: It is assumed that the reader is familiar with terms such as Multilayer Perceptron, delta errors or backpropagation. If not, it is recommended to read for example a chapter 2 of free online book ‘Neural Networks and Deep Learning’ by Michael Nielsen.
Convolutional Neural Networks (CNN) are now a standard way of image classification – there are publicly accessible deep learning frameworks, trained models and services. It’s more time consuming to install stuff like caffe than to perform state-of-the-art object classification or detection. We also have many methods of getting knowledge -there is a large number of deep learning courses/MOOCs, free e-books or even direct ways of accessing to the strongest Deep/Machine Learning minds such as Yoshua Bengio, Andrew NG or Yann Lecun by Quora, Facebook or G+.
Nevertheless, when I wanted to get deeper insight in CNN, I could not find a “CNN backpropagation for dummies”. Notoriously I met with statements like: “If you understand backpropagation in standard neural networks, there should not be a problem with understanding it in CNN” or “All things are nearly the same, except matrix multiplications are replaced by convolutions”. And of course I saw tons of ready equations.
It was a little consoling, when I found out that I am not alone, for example: Hello, when computing the gradients CNN, the weights need to be rotated, Why ?
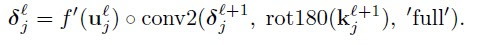
The answer on above question, that concerns the need of rotation on weights in gradient computing, will be a result of this long post.
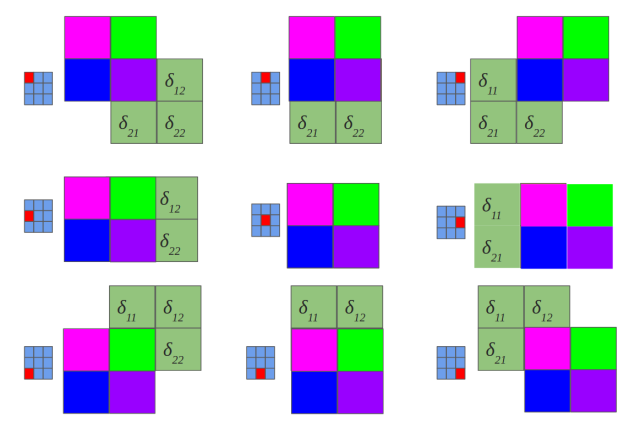
We start from multilayer perceptron and counting delta errors on fingers:

We see on above picture that 
But how do we connect concept of MLP with Convolutional Neural Network? Let’s play with MLP:

If you are not sure that after connections cutting and weights sharing we get one layer Convolutional Neural Network, I hope that below picture will convince you:
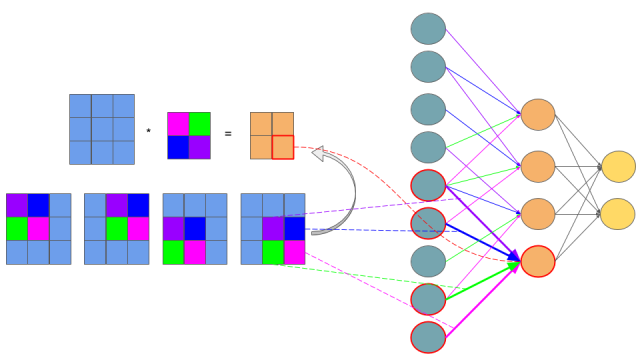
The idea behind this figure is to show, that such neural network configuration is identical with a 2D convolution operation and weights are just filters (also called kernels, convolution matrices, or masks).
Now we can come back to gradient computing by counting on fingers, but from now we will be only focused on CNN. Let’s begin:
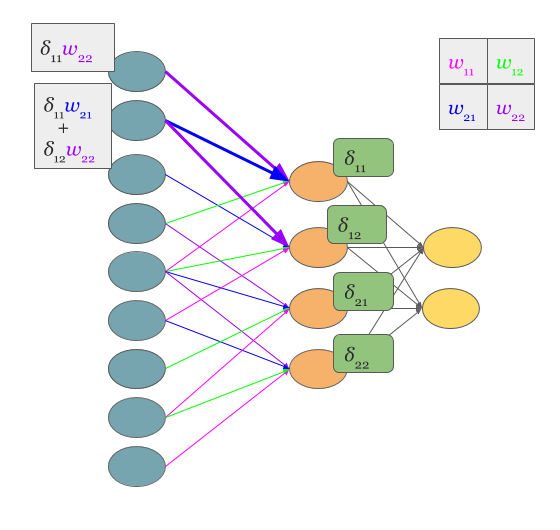
No magic here, we have just summed in “blue layer” scaled by weights gradients from “orange” layer. Same process as in MLP’s backpropagation. However, in the standard approach we talk about dot products and here we have … yup, again convolution:
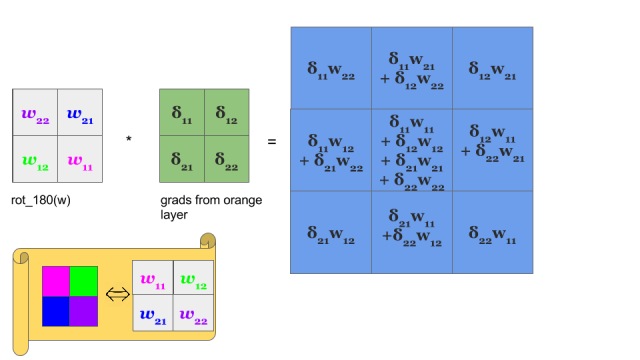
Yeah, it is a bit different convolution than in previous (forward) case. There we did so called valid convolution, while here we do a full convolution (more about nomenclature here). What is more, we rotate our kernel by 180 degrees. But still, we are talking about convolution!
Now, I have some good news and some bad news:
- you see (BTW, sorry for pictures aesthetics 🙂 ), that matrix dot products are replaced by convolution operations both in feed forward and backpropagation.
- you know that seeing something and understanding something … yup, we are going now to get our hands dirty and prove above statement 🙂 before getting next, I recommend to read, mentioned already in the disclaimer, chapter 2 of M. Nielsen book. I tried to make all quantities to be consistent with work of Michael.
In the standard MLP, we can define an error of neuron j as:

where 
and for clarity, 
But here, we do not have MLP but CNN and matrix multiplications are replaced by convolutions as we discussed before. So instead of 
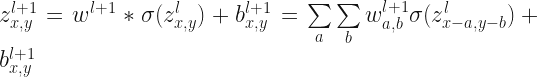
Above equation is just a convolution operation during feedforward phase illustrated in the above picture titled ‘Feedforward in CNN is identical with convolution operation’
Now we can get to the point and answer the question Hello, when computing the gradients CNN, the weights need to be rotated, Why ?
We start from statement:
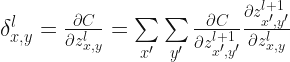
We know that 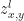
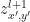

First term is replaced by definition of error, while second has become large because we put it here expression on 
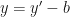

If 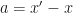


OK, our last equation is just …

Where is the rotation of weights? Actually 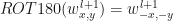
So the answer on question Hello, when computing the gradients CNN, the weights need to be rotated, Why ? is simple: the rotation of the weights just results from derivation of delta error in Convolution Neural Network.
OK, we are really close to the end. One more ingredient of backpropagation algorithm is update of weights 
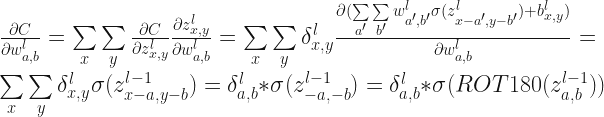
So paraphrasing the backpropagation algorithm for CNN:
- Input x: set the corresponding activation
for the input layer.
- Feedforward: for each l = 2,3, …,L compute
and
- Output error
: Compute the vector
- Backpropagate the error: For each l=L-1,L-2,…,2 compute
- Output: The gradient of the cost function is given by


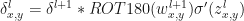
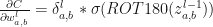
The end 🙂


Reblogged this on mugedblog and commented:
Kolejny post Grześka, tym razem o Konwolucyjnych Sieciach Neuronowych!
LikeLiked by 1 person
It is awesome!
Weeks ago, I met the same puzzle like yours. It is true that few explanations are made on it during the online resources,yet there is still some, like:
http://andrew.gibiansky.com/blog/machine-learning/convolutional-neural-networks/
This blog let me figure out how to use the BP in Conv(though the notations used in it are totally different with which in Michael Nielsen’s book, which is awkward…).
What’s more, using the toolkits designed for ML like Theano makes the backpropgation of delta no more a question. Theano use the method called ‘auto differentiation’, which can get the partial derivatiations from the Cost with respect to w&b just in one line code. I think that’s why most tutorials jump over BP in non-fully-connected-NN: there is no need to calculate derivatiation manually.
LikeLike
I completely agree with you! Automatic differentiation is a big switch, not only in Deep Learning (for example PyMC 3 for Bayesian statistical modeling, that is based on Theano ). However, I like to fully understand the matter and I hope that this blog post would be helpful for learners 🙂
LikeLiked by 1 person
If I have neural network that consist of different kind of layers, for instance , the network architecture is [input->conv layer->ReLU->fullyconected layer->softmax layer how do I derive gradient descent?
LikeLike
tensor flow do the same?
LikeLike
Reblogged this on My Blog.
LikeLike
thank you! there is not much well explained backpropagation example on the net.
LikeLiked by 2 people
Pingback: Convolutional Autoencoder for Dummies – Grzegorz Gwardys
Amazing! Your’s is the best explanation so far i found on the internet!!
Would it be please possible to upload a youtube video of your derivation, please?
Thanks!
LikeLiked by 1 person
Thank you for kind words 🙂 Youtube video … interesting concept, maybe some day 😉
LikeLike
It’s a really helpful explanation, but I still have some question:
1. Why would we ROT180() when calculating the gradient?
2. The size of the gradient? I mean let’s say l-th layer has like 5 x 5 delta, and the value of (l-1)-th is 9 x 9, how would we solve that?
LikeLike
Good Job 🙂
And, what about update of biases?
\frac{\partial C}{\partial b^l_{i,j}}=\frac{\partial C}{\partial z^l_{i,j}}\frac{\partial z^l_{i,j}}{\partial b^l_{i,j}}=\delta^l_{i,j}\rightarrow \triangle b^l=\delta^l
LikeLiked by 1 person
Thanks a lot. Its the best tutorial on CNN. It is useful for all the people in neural networks community.
LikeLike
Thank you for kind words 🙂
LikeLike
In one of the pictures (the one under “yup, again convolution:”, with rot_180(w) * grads from orange layer), are the values correct? The picture shows convolution of the rotated weight kernel (w22, w21, w12, w11) by deltas, but the output is as if deltas were convoluted by the normal (not rotated) weight kernel (w11, w12, w21, w22). So the derived delta at col=1 and row=0 (blue matrix) is shown as (d11 * w21 + d12 * w22), where it actually should be (d11 * w12 + d12 * w11), if convolved by the rotated weights matrix.
Am I missing something? Thanks!
LikeLike
Yup, it’s OK. We are talking about convolutions not correlations and that’s why we need another rotation. That’s why next image is also OK 😉
LikeLike
Thank you for answering. I realized my “convolution” was in fact incorrect, I was not reversing the order and as a result I was getting incorrect output. Wikipedia helped with that:
https://en.wikipedia.org/wiki/Kernel_(image_processing)
Thanks a lot!
LikeLike
But does it matter? It just learns a set of weights that in the end it uses to classify images. Do frameworks like TensorFlow, Theano use correlations or actual convolutions in their CNN layers?
LikeLike
It does matter to be precise in such kind of ‘math posts’. If we talk about ”FFT versions’ (look at: https://arxiv.org/abs/1312.5851) then we have surely convolutions.
LikeLike
It looks like the final operation can be made a little simpler by introducing a “full correlation” operation. Full correlation would work like the regular correlation (dot product) only with the addition of zero padding, like in the case of full convolution.
Since convolution works like an inverted correlation, and the final operation uses convolution by a rotated kernel (also an inverse of sorts), both can be replaced by a single “full correlation” operation by the original (not rotated) kernel.
Below is a Scala function implementing the “full correlation” operation. Matrices are stored as arrays of floats in [row0, row1, …] format.
def fullCorr2d(a: Array[Float], aCols: Int, aRows: Int,
k: Array[Float], kCols: Int, kRows: Int)(x: Int, y: Int): Float = {
assert(kCols == kRows) // expect a square kernel matrix
val k2 = kCols / 2
var sum = 0f
for (j <- 0 until kRows) {
for (i = 0 && aCol >= 0 && aRow < aRows && aCol < aCols) {
val w = k(j * kCols + i) // kernel weight
sum += w * a(aRow * aCols + aCol)
} // input values outside of the valid range are zero and not needed
}
}
sum
}
LikeLike
I have another question, regarding the reverse (by rotated kernel) convolution.
If the original convolution (during forward pass) was applied with a stride > 1, does that mean that during the back propagation phase the reverse convolution (by the rotated kernel) also needs to be applied with the same stride?
It seems that that should be true, given this equation (shown above using math symbols):
delta(layer,x,y) = [ delta(layer+1,x,y) conv ROT180(kernel(layer +1)) ] * activationDerivative(output(layer,x,y)) <<< output matrix size depends on stride
Thanks a lot!
LikeLike
First: I think you made a typo in the overview; step 2, Feedforward. You’ve got “z_{x,y}^l=w_{x,y}^l*\sigma(z_{x,y}^l)+b_{x,y}^l” written, but z_{x,y}^l appears twice. The z_{x,y}^l inside the sigmoid should be z_{x,y}^(l-1) or something like that, because convolution operates on the previous layer (or the input), right?
Second: This is literally the best article on conv nets I have ever read. Thank you.
LikeLike
Sorry to submit another post, but:
You use the notation a_{x,y}^l for the activation of some filter at some (x,y) in an image. Why would you use the same notation for bias and weight terms? They don’t change based on positions in an input image; they ‘belong’ to the filter. Also, I assume that in the feedforward step, compute z_{x,y}^l for each layer means compute z_{x,y}^l for each pixel in each layer. Is that correct?
LikeLike
Adam, trying to answer your questions:
1. I do not see any “z_{x,y}^l=w_{x,y}^l*\sigma(z_{x,y}^l)+b_{x,y}^l”. However, there is an eq. “z_{x,y}^(l+1)=w_{x,y}^l*\sigma(z_{x,y}^l)+b_{x,y}^(l+1)” so it seems legit.
2. I tried to be consistent with Michael Nielsen as much as possible. While he has z_j and b_j I have two-dimensional case so I have z_{x,y} and b_{x,y}. Of course, you can use matrix notation without any x,y positions.
3. In this blog post I simplified a problem, because we do not have here many feature maps at the same level – only one. ^l defines index of layer.
LikeLike
First, thanks for this! definitely helps understand backprop for convolution layers!
But question, you have this eq, “z_{x,y}^(l+1)=w^(l+1)*\sigma(z_{x,y}^l)+b_{x,y}^(l+1)” , which says that the (x,y)th neuron in the feature map (only one map in your post) gets w^(l+1)*\sigma(z_{x,y}^l) PLUS the (x,y)th bias. That would suggest that the bias matrix is the same size of the feature map. Or that there is a bias for each neuron.
Is this correct?
In Michael Nielsen’s book, chapter 6, where he discusses convolution neural networks, he walks us through building a CNN for the MNIST problem. In his equation for the output of the (j,k)th neuron b has no subscripts. He states “Each feature map is defined by a set of 5×5 shared weights, and a single shared bias. ” (again only one feature map in your post as per previous comment). I know the size of the weights was for his CNN and that it could be anything. BUT what confuses me is the single shared bias part.
In your equation there are more than one bias for l, but if there is only one feature map in your example then shouldn’t there be only one bias? and the equation be: “z_{x,y}^(l+1)=w^(l+1)*\sigma(z_{x,y}^l)+b^(l+1)”??
Since the same weights are applied to EACH neuron in the feature map, it would make sense that the same bias value be applied to each one as well. Isn’t this how they detect the same feature??
Your post helped me GREATLY understand the backprop aspect for it, but really made me confused in the forward part now..
LikeLike
Regarding the 2nd answer, I think what Adam meant, is that there is only 1 bias for each filter. The equation shows that there is 1 bias for each entry of the feature map.
LikeLike
That’s odd; I see an incorrect feedforward equation in my browser. Anyway, thanks for the notation cleanup.
LikeLike
In the example you give, you have a filter of size 2×2, and an input of size 3×3, with an output of size 2×2. If both the filter and input were size 3×3, the output would be size 1×1, and there would be no weight sharing; the errors for each neuron correspond only to the output by a single weight (no sums of deltas). Is that true? If so, why is it said that convolutional neural nets share weights always (since with 3×3 filters there is no weight sharing)?
LikeLike
What you are describing could be equally well achieved by multiplying a 1*9 matrix with a 9*1 matrix – ie it would be analagous to a fully-connected NN with a 9-unit and 1-unit layer.
Therefore there would be no need to treat it as a convolution.
LikeLike
The best tutorial on CNN I have ever seen. It’s time for YouTube channel for sure!
LikeLike
why w{x,y}*a ,w need subscript when use the symbol of convolution? its each element would be use no matter what the position is.
LikeLiked by 1 person
Yup, you’re right, thx. I see also that Adam Mendenhall was right. Lesson for me – if you are tired, do not review such things (even own work).
LikeLike
hi grzegorzgwardys,
Thanks for the great explanation. I am working with my professor to apply a CNN to a gesture recognition problem. In this post, for simplicity I assume, you mentioned doing the backpropogation with an input that was only 2 dimensions (1 layer deep instead of multiple) as well as a filter that was only 2 dimensions (1 layer deep). However, in our code, as forward propagate, your inputs to the convolution become increasingly deep, and your filters likewise grow in the z (depth) dimension. I understand the whole idea of backpropogating with the flipped filter, however, how do you work with differing depths during backprop? If I have an input that is 10 deep, and I convolve it with a filter that is 10 deep, I get out a 1 deep feature map. So when I backprop the error to that 1 deep feature map, I can’t just convolve that 1 deep feature map delta with the 10 deep filter that I used in the forward propogation. Or can I? Any help in this area or pointing towards help would be greatly appreciated. Thank you.
LikeLike
OK, our last equation is just … the next equation i think has something wrong, because it is not the defination of convulution because you could see both x’ and y’ in delta and w have the some sign. the should have the different signs that is the defination of covolution. I think the w should roate 180 and the sign x’ of w change from +1 to -1. so that will be ok.
LikeLike
Hi grzegorzgwardys: Thank you for the clear explanation, it does make sense to me. However, when I check the source code of BP in caffe, I found they just do the transpose operation instead of rotation by 90degree: dX = transpose(W) * dY. So, why is difference?
LikeLike
I find color mismatch with the weight co-efficient in actual weight matrix (no rotation). Violet should be placed at w11.
LikeLike
You wrote: “Above equation is just a convolution operation during feedforward phase illustrated in the above picture titled ‘Feedforward in CNN is identical with convolution operation’”.
Actually the above equation is a full convolution whereas in the picture ‘Feedforward in CNN is identical with convolution operation’ you described a valid convolution.
LikeLiked by 1 person
Hi, isn’t there a derivative of sigmoid missing in last equation for gradient?
LikeLike
Hi, your blog is really great. I have some confusion:
In the back propagation of CNN, there has 6 variables: x, y, a, b, x’, y’. But you don’t explain what it is. Can your give me more details about these variables. Thanks.
LikeLike
Reblogged this on ARUNEKUMAR BALA and commented:
derivative of convolution layer in conv neural nets
LikeLike
Great article!
For #3 on the bottom of the article:
If I am making a neural network that looks like this: http://pubs.sciepub.com/ajme/2/7/9/image/fig2.png
The Classification neural net will have an output layer of 10 neurons, making the Cost function C = 1×10 matrix
How can I multiply C by sigmoid prime of zL like in your #3 equation?
Isn’t sigmoid prime of zL (for the feature learning conv net) a 1x1x300?
How do I get delta L (delta of last layer of feautre learning – conv neural net)?
LikeLike
Hi dear Grzegorz,
very good article. I have worked with MLPs for some time now and it is nice to see, that CNN are a special case of MLPs.
Something I didn’t understand is the following:
when using MLPs, for example as a classificator, one uses the classes as output and the data to be classified as input. So the error is calculated as difference between actual output and wanted output.
Now having a CNN to classify images, on what does one calculate the error of the pooling layers? There is no expected output of the convolution, as far as I can see.
LikeLike
Perfect derivation, thank you very much!
LikeLike
Great! Thank you!
LikeLike
Pingback: 反向传播算法 | Sandezi
Two issues about the weights updating equation, I think it should be like:
\frac {\partial J} {\partial w_{a,b}^l}
= \sum\limits_{x} \sum\limits_{y}
\frac {\partial J} {\partial z_{x,y}^l}
\frac {\partial z_{x,y}^l} {\partial w_{a,b}^l}
= \sum\limits_{x} \sum\limits_{y}
\delta_{x,y}^l
\frac {\partial (\sum\limits_{a’} \sum\limits_{b’}
w_{a’,b’}^l \sigma(z_{x-a’,y-b’}^{l-1}) + b_{x,y}^l )}
{\partial w_{a,b}^l}
= \sum\limits_{x} \sum\limits_{y}
\delta_{x,y}^l \sigma(z_{x-a,y-b}^{l-1})
= \delta^l * \sigma(z_{-a,-b}^{l-1})
= \delta^l * \sigma(ROT180(z_{a,b}^{l-1}))
Issue 1:
After the 2nd “=”, \sigma(z_{x-a’,y-b’}^{l-1}), should be ^{l-1}
Issue 2:
After the 5th “=”, \delta_{a,b}^l –> \delta^l, _{a,b} not needed.
I am not very familiar with the formation of discrete convolution, so it’s not very sure about the 2nd issue.
LikeLike
all clear, but one question, how the partial derivative dC/db^l, where b^l is the bias of the l layer, is computed?
LikeLike
and the pooling layer doesn’t affect and it s not important during backpropagation step?
LikeLike
Oh well, what the hell, this stuff isn’t clear from the first glance and I really don’t like the MOOCs ignoring this, I only cared to write stuff with gates and reverse automatic differentiation which is probably how the deep learning libraries do their stuff. Anyway, it seems your blog has become a pilgrimage site for deep learning enthusiasts. I came, and many will come after me, year after year, until CNN is out fashioned, which I hope it never does.
LikeLike
Pingback: 深度学习框架Keras使用心得 – 科网
Backpropagate the error: For each l=L-1,L-2,…,2 compute \delta_{x,y}^l =\delta^{l+1} * ROT180(w_{x,y}^{l+1}) \sigma'(z_{x,y}^l)
If you compute the derivative carefully, I believe you’d get sigma(z^(l+1)) instead of sigma(z^(l)). What do you think?
LikeLike
how keras/tensorflow uses BP to calculate auto differenciation so that we no need to calculate it manually if we use adam optimizer?
LikeLike
hi grzegorzgwardys, thanks for your great explanation. I understand it roughly, but I still have some questions:
1. You said that $z_{x,y}^{l+1}=\omega_{a,b}^{l+1}\sigma(z^l_{x,y})+b^{l+1}_{x,y}=\sum_a\sum_b \omega_{a,b}^{l+1}\sigma(z^l_{x-a,y-b})+b^{l+1}_{x,y}$, I can understand from convolution. But in your third picture, $z11=\delta_{11}\omega_{22}$. Is there something wrong?
2. $\sum_x\sum_y\delta_{x,y}^l\sigma(z_{x-a,y-b}^{l-1})\\
=\delta^l\sigma(z_{-a,-b}^{l-1})$ I don’t know the reason of this equation.
Wait for your reply, a beginner.
LikeLike
Pingback: From 0 to Convolutional Neural Networks | David Mata blog
Thanks a lot for a clear and concise explanation of backpropagation in CNN! To find the deltas of a given layer, we do “full” convolution as mentioned in the article.
But when calculating the errors with respect to filter weights, we do a “valid” convolution between deltas of the convolutional output and 180 degrees rotated version of the input layer (layer before convolution) correct?
LikeLike
In the figure ‘Feedforward in CNN is identical with convolution operation’, the upper left corner of the upper left kernel is pink while the upper left corner of the four kernels below is purple. Is this a mistake?
LikeLike
Can you sign the indices of a convolution formula less confusing? using “signal” for convolution in a CNN is confusing 😦
LikeLike
I am very sorry that due to time constraints I could not afford to respond. As you may guess I stopped blogging 6 years ago (2016) and that is why all the questions that have arisen since then remained unanswered. Now it is very difficult for me to answer all of them or what is even harder – to fix potential errors in the blog post that were found by careful readers.
Looking for a solution I see two options:
– all comments were approved so if there is an error found by someone, next reader can read both my blog post and comments to have a full picture; such person can also reply to a comment where someone was correct – it will be very helpful for all!
– the world does not stand still, there appeared many great resources about CNN since 2016 – my favorite is https://www.youtube.com/watch?v=Lakz2MoHy6o done be Omar Aflak, I am sure that this video will clarify all doubts!
LikeLike